•
Abstract
Energy benchmarking has been used to compare energy efficiency of buildings. The conventional benchmarking uses Energy Use Intensity (EUI, kwh/㎡·yr) per ‘use type’ (e.g., residential, office, and educational). However, it could lead to a false comparison when two buildings of a same ‘use type’ have different thermal characteristics such as HVAC, building envelopes, and operational hours. We conducted K-means clustering analysis with regard to monthly energy data of 10,750 buildings. It was found that those buildings can be clustered into four representative patterns. Then, we compared the clustering results of all buildings and buildings of each use type. It was found that the representative energy use pattern of each use type was very similar to it of all use type, meaning that a building use type might not reflect the monthly operation pattern. Therefore, it could be more meaningful to compare two buildings of a same pattern than of a same use type.
•
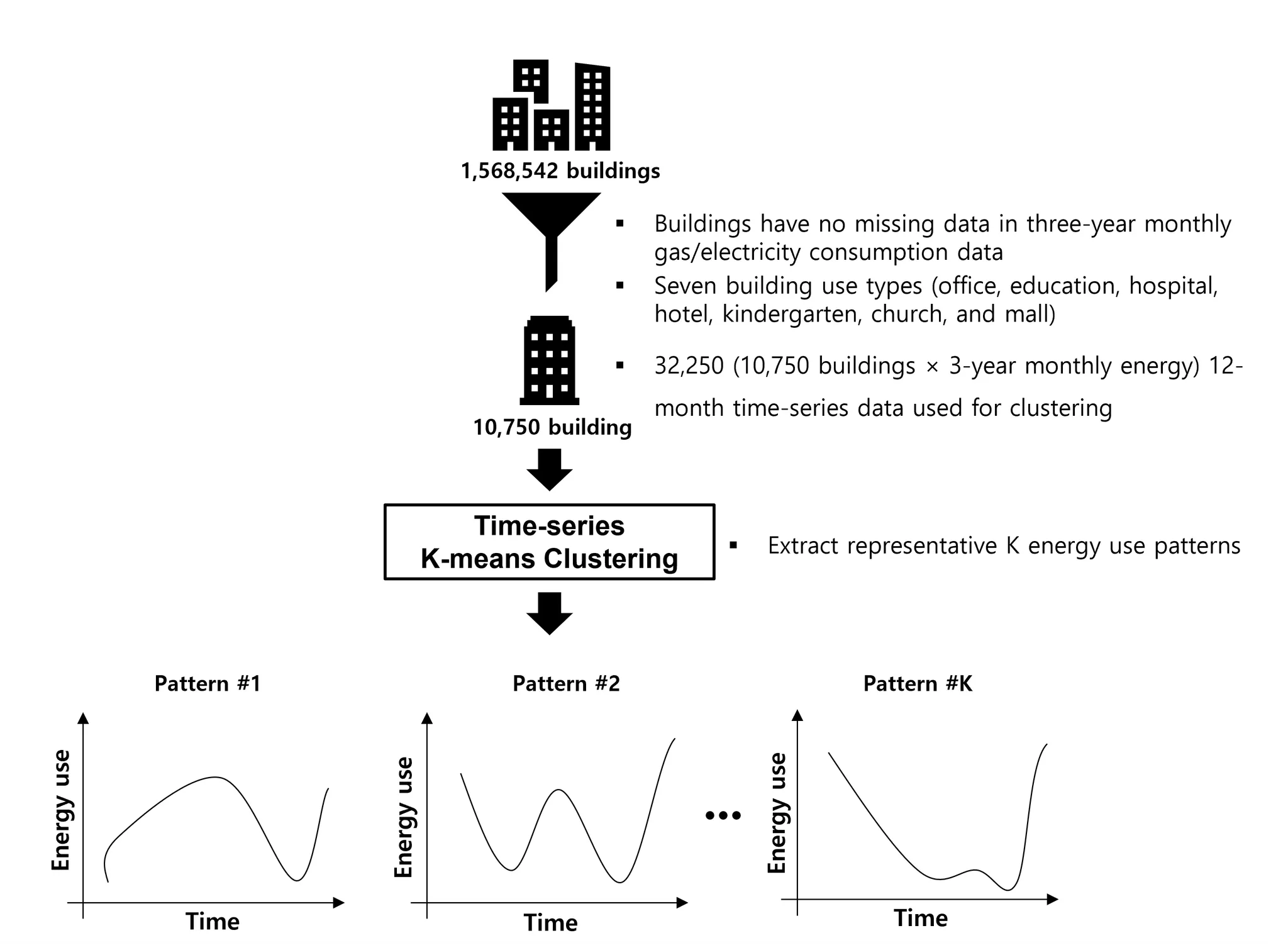
Analysis process
•
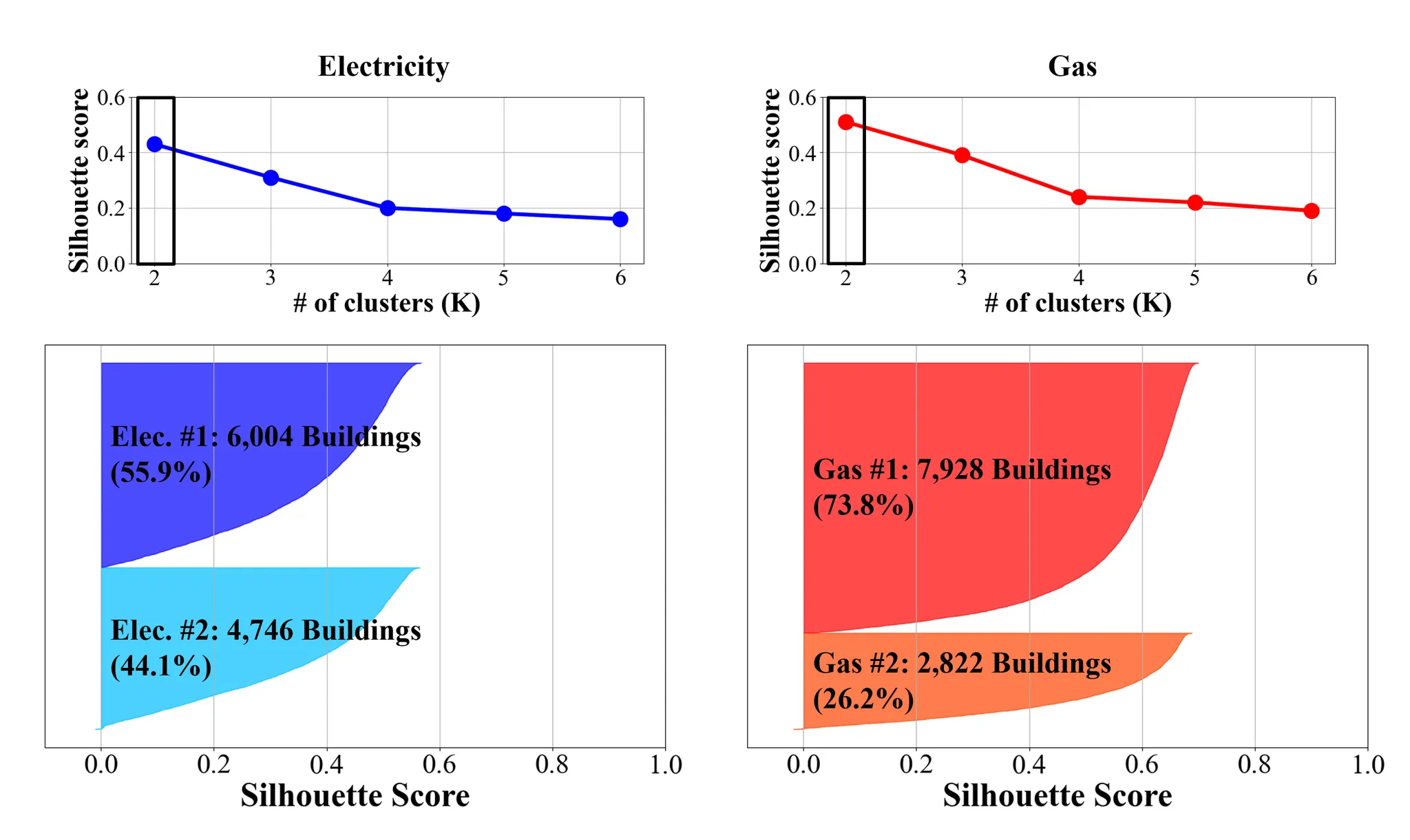
Find the optimal K using Silhouette score
◦
When K=2 respectively for both electricity and gas consumption data, each building is optimally matched to its own cluster.
•
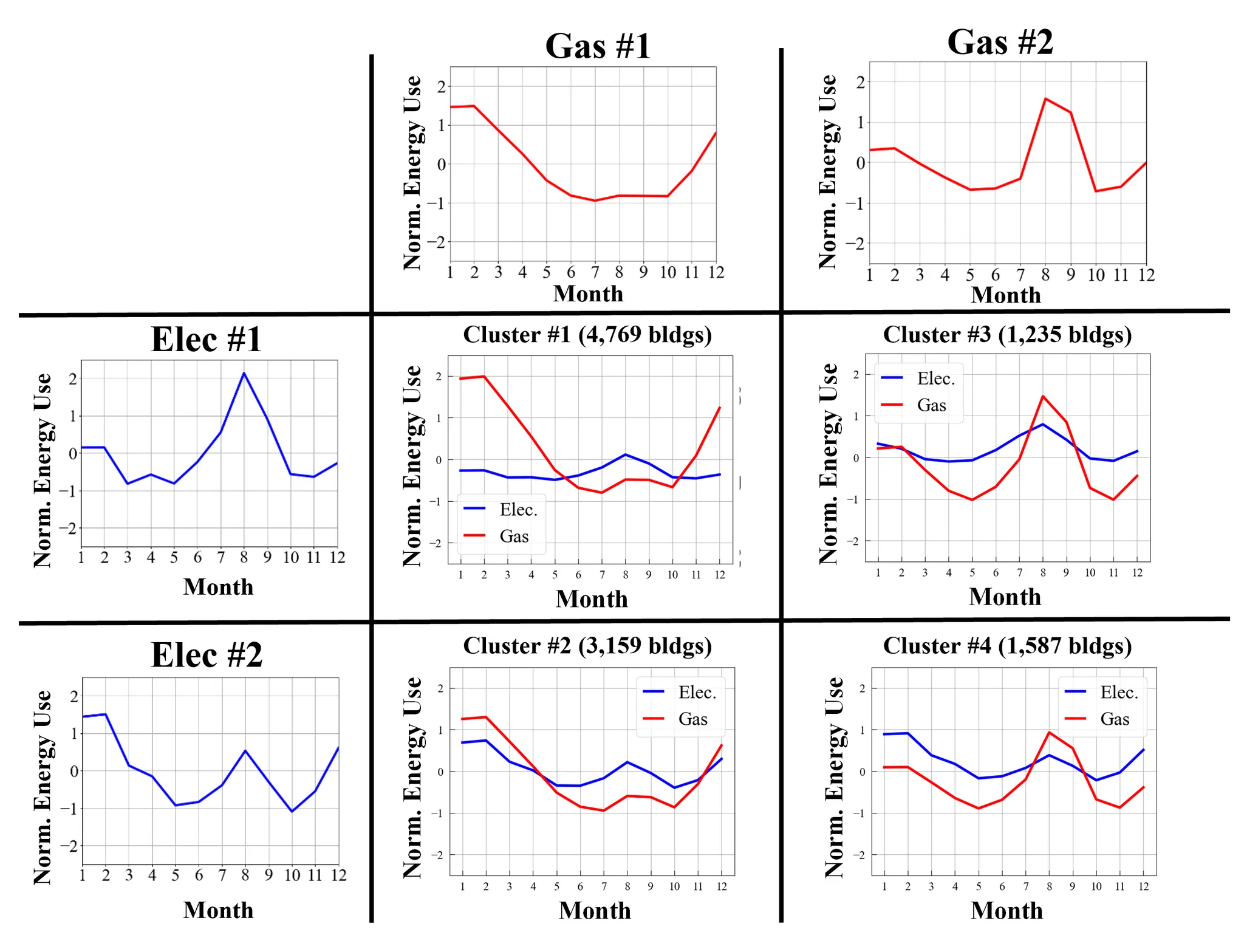
Representative four energy use patterns
•
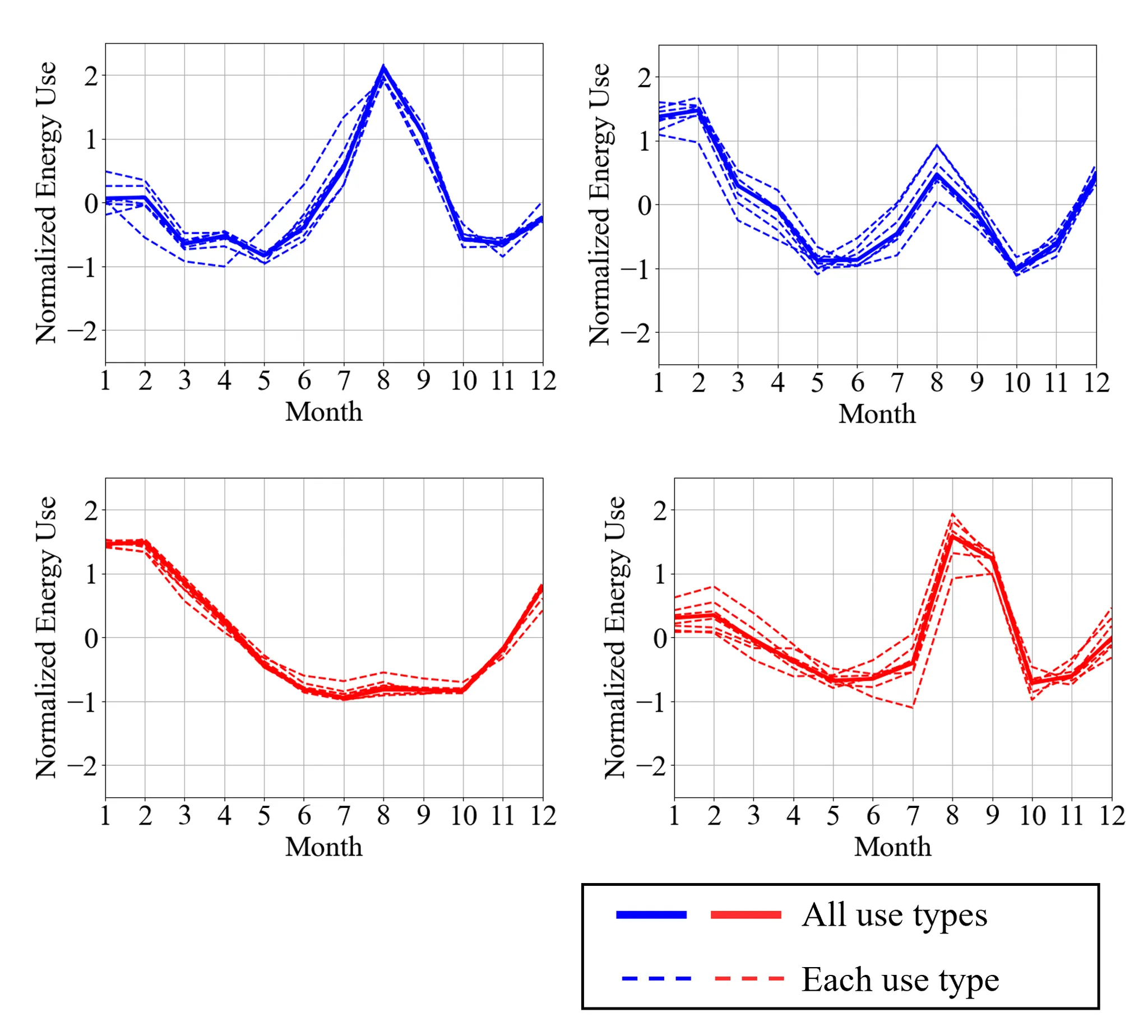
Clustering energy data of each building use type
◦
The representative energy use pattern of each use type was very similar to it of all use types together.